Published: January 2, 2024 | Last Updated: December 11, 2025
A Deep Dive into Data Center Redundancy

Table of Contents
It’s always a good idea to have a backup plan, as well as a backup plan to the backup plan, to ensure your data center is operating at its best. As businesses continue their digital transformation journeys, more critical and sensitive data will be stored in data centers, as well as in the cloud, making redundancy measures more important than ever.
We’ll discuss what data center redundancy is, the types of redundancy data centers can have, and what to expect with different redundancy levels and data center tiers if you’re planning a migration.
What is Data Center Redundancy?
Data center redundancy can maximize productivity, improve safety, and bolster organizational trust. Data center disruption can come in many forms: natural disasters, power outages, equipment failure, or even human actions – whether accidental or intentional. The more data centers safeguard against these disruptions, the more business operations and data will be protected.
What’s the Difference Between Failover and Redundancy?
Failover and redundancy work together, but there are key differences between the two. Failover is the act of moving from one component or system to the other in the event of component failures. Redundancy is the practice of having multiple components available to boost system availability and have a plan for failover in the first place.
Why is Redundancy in a Data Center Important?
Data center redundancy is necessary because even minor disruptions to data centers can be damaging. Downtime can cost businesses anywhere from $427 to $9,000 per minute, according to SolarWinds.
Redundancy models are also important because many data centers include uptime as part of their service level agreements (SLAs). Data center customers may also offer these uptime guarantees, by extension, to their end-users. Without a reliable data center and predictable uptime, the costs of downtime can be too much to overcome.
Lastly, business continuity is largely determined by uptime, which is significantly supported by redundancies. Planning for component failure and putting redundancies in place will improve uptime and business continuity by extension.
5 Types of Data Center Redundancy
Data center redundancy can take one of five forms, or any combination of these types: power, cooling, network, backup, and server and hardware.
Power Redundancy
Power redundancy offers ongoing operation even in the face of a power outage. To achieve this, facilities need to have multiple sources of power. This may be additional utility feeds, uninterruptible power supplies (UPS), and backup generators. The type of power backups can determine the level of coverage the redundancy provides. For example, UPS systems only offer temporary power, but generators can power data centers for much longer.
Cooling Redundancy
Without cooling redundancy, data center equipment could overheat, which can cause damage and loss of data. Multiple cooling systems can help prevent this damage, such as backup power for cooling and additional air conditioning units. In the case of liquid cooling, redundant cooling loops may be used by installing multiple sets of pipes, heat exchangers, and pumps. Facilities might also incorporate hot/cold aisle configurations to improve cooling efficiency and airflow on IT equipment.
Network Redundancy
Network redundancy is all about providing backup for the paths data can take in a data center. Redundancies can be added using additional switches, routers, and fiber optic cables. Network disruptions can also be countered using protocols that prevent loops and guarantee seamless failover, such as spanning tree protocol (STP).
Backup Redundancy
Data replication, cloud-based backup solutions, and offsite backups are all measures that can improve backup redundancy. Hardware failures, cyberattacks, and natural disasters can all lead to a loss in data, so backup redundancy is concerned with securing multiple copies of data to prevent this loss. Having a second data center in a geographically diverse location serves as an additional backup redundancy measure. In the event of a disaster or outage affecting one location, the secondary center ensures business continuity and safeguards against region-specific challenges, minimizing downtime and data loss.
Server and Hardware Redundancy
Redundant components providing coverage for server and hardware redundancy can be configured in a failover or load-balancing mode to transition seamlessly into operation in the event of hardware failures. Redundant servers, network devices, and storage arrays are three pieces that can improve resiliency.
What Are the Data Center Redundancy Levels?
Data center redundancy levels should be used in accordance with the level of coverage your organization needs. You may require more redundancy if you’re dealing with more critical data or stand to lose a lot in revenue or operations with small amounts of downtime.
Redundancy levels at data centers are defined by N, where N equals the minimum number of required components to operate a data center at full capacity.
N Redundancy
N redundancy is defined as the base-level infrastructure that is necessary to run a data center at its fullest capacity. There is no backup for any components in a data center with N redundancy, so failure of one component would equal downtime.
N+1 Redundancy
The most common redundancy level in data centers is N+1 redundancy. For every N component in a data center, N+1 redundancy means that there is one backup component available. However, this means that if two or more components fail at the same time, the data center would still have downtime.
N+2 Redundancy
Taking it one step further, N+2 redundancy offers higher fault tolerance by providing two backup components for every N component. Two components can fail without the data center experiencing downtime.
2N Redundancy
2N redundancy is considered the highest level of redundancy available and is also called “fully fault-tolerant” redundancy. Instead of just having one or two extra backups for each component, the data center has two complete sets of components. This means that even if all components in one set happen to fail, the data center can continue to operate as normal.
3N/2 Distributed Redundancy
While 3N/2 distributed redundancy may sound more secure than 2N redundancy, it actually has more in common with N+1 redundancy. There are two backup components for every N component, but instead of being dedicated to one site, the components are distributed across three different sites. This can help improve uptime in the face of single-site failures, but is not as secure as 2N redundancy.
How Redundancy is Connected to Data Center Tier Levels
Redundancy models are closely connected to data center tier levels. These tier levels, as defined by Uptime Institute, can tell a business a lot about a data center’s level of redundancy before ever touring the facility. There are four data center tier levels, each with its own standards for infrastructure, fault tolerance, and capabilities.
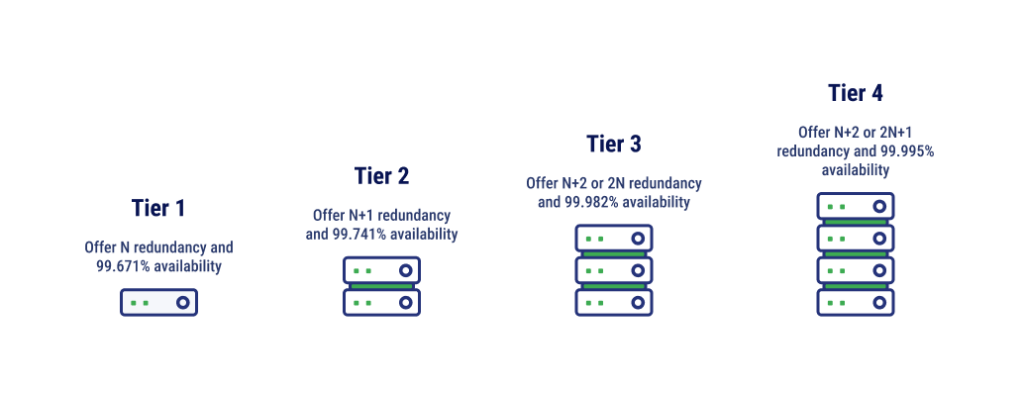
Tier 1 Data Centers
Tier 1 data centers offer N redundancy and 99.671% availability. These facilities have one path that distributes cooling and power and there are no redundant components. Customers can expect about 28-29 hours of downtime per year.
Tier 2 Data Centers
Tier 2 data centers have some redundant components and are most closely associated with N+1 redundancy. These data centers offer 99.741% availability, but still have only one path for power and cooling. Customers can expect about 22 hours of downtime per year at maximum.
Tier 3 Data Centers
Tier 3 data centers are most likely N+2 or 2N redundant facilities, with multiple paths for cooling and power. They also tend to have concurrent maintainability, which means that critical components can be repaired or even replaced without causing a disruption to operations. Tier 3 data centers have 99.982% availability. Downtime is guaranteed to be less than 1.6 hours per year.
Tier 4 Data Centers
Availability and redundancies are highest at Tier 4 data centers, which have 2N or even 2N+1 redundancies. These data centers are fault-tolerant and have 99.995% availability. Fault tolerance means that if one or more components fail, no matter what they are, the data center has backups in place to keep operations moving. Downtime is very rare at Tier 4 data centers – less than 0.5 hours per year.
Choosing the Right Data Center to Maintain Business Continuity
Even though it may seem that choosing the highest redundancy levels and the highest tier level for a data center is the right way to go, it’s important to balance the amount of redundancy your business needs with the costs of choosing higher-tier data centers. Start by thinking about your most critical workloads, how much downtime your organization can tolerate, and what you would need in place to support your business continuity.
TierPoint’s 40 state-of-the-art, interconnected data centers have redundant infrastructure, carrier-neutral connectivity, and offer direct connections to cloud providers. Edge computing and low-latency connection capabilities also allow our customers to connect to their end-users faster. Learn more about our data centers and talk to us to find a solution that’s right for you today.
FAQs
A data center can incorporate redundancies via power, cooling, storage, networks, hardware, and more.
There is often a direct relationship between redundancy and high availability – the more redundancies data centers have in place, the better availability will be for customers.
Data centers ensure high uptime and availability by implementing redundancies as additional components for power, networking, servers, hardware, storage, and more.
Table of Contents
-
Data Center
Feb 19, 2026 | by Chad Norwood
How AI in Data Centers Is Transforming the Future of IT
VIEW MORE -
Data Center
Jan 26, 2026 | by Chad Norwood
Top 10 Data Center Industry Trends in 2026
VIEW MORE -
Cloud
Jul 15, 2025 | by Matt Pacheco
How Hyperconverged Infrastructure (HCI) Works with Private Cloud
VIEW MORE